
Consultas de banco de dados lentas drenam silenciosamente o desempenho do seu aplicativo, frustrando usuários e inflacionando custos de infraestrutura. Essas cinco técnicas comprovadas ajudarão você a eliminar gargalos de latência e entregar a experiência rápida e responsiva que seus usuários esperam.
Uma abordagem que simplifica a otimização de banco de dados é criar com Adalo—um construtor de aplicativos sem código para aplicativos web e aplicativos iOS e Android nativos orientados por banco de dados—uma versão em todas as três plataformas, publicada na Apple App Store e Google Play. O banco de dados integrado do Adalo oferece latência de API zero, enquanto sua infraestrutura gerencia caching e otimização de consultas automaticamente, para que você possa se concentrar no seu aplicativo em vez de ajuste manual de banco de dados.
Quer você esteja otimizando um sistema existente ou lançando um novo MVP, colocar seu aplicativo nas lojas de aplicativos rapidamente significa alcançar o maior público possível com notificações push e desempenho nativo. Veja como deixar suas consultas de banco de dados extremamente rápidas.
A latência de consultas de banco de dados pode arrastar o desempenho do seu aplicativo para baixo, frustrando usuários e aumentando custos. Quer você esteja criando uma ferramenta interna simples ou um aplicativo voltado para o cliente com milhares de usuários, consultas lentas criam gargalos que se propagam por todo o seu sistema. Veja como corrigir:
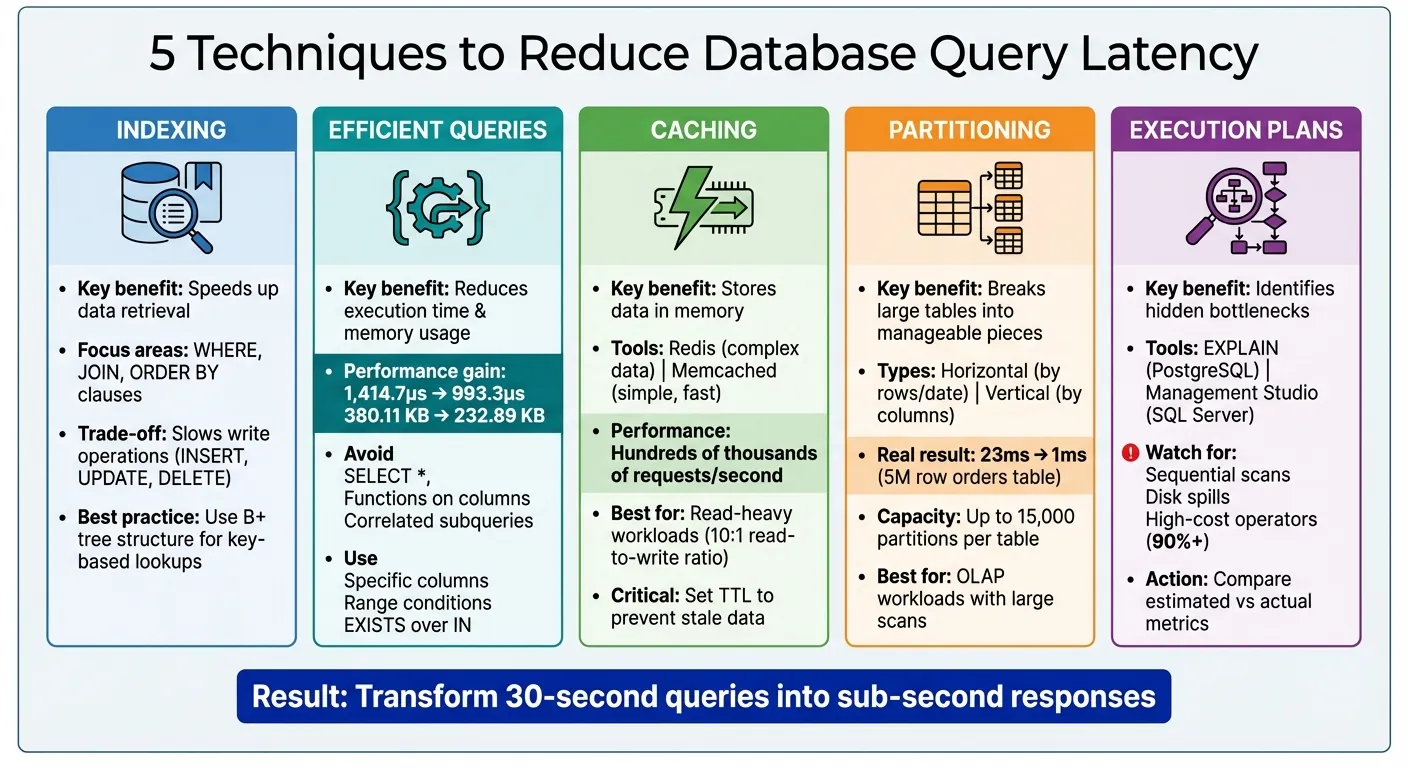
- Indexação: Use índices para acelerar a recuperação de dados direcionando colunas em
WHERE,JOIN, eORDER BYcláusulas. Evite sobre-indexação para prevenir operações de escrita mais lentas. - Consultas Eficientes: Evite
SELECT *, otimizeWHEREcondições para uso de índice e minimize junções ou subconsultas desnecessárias. - Cache: Armazene dados frequentemente acessados na memória usando ferramentas como Redis ou Memcached para reduzir a carga do banco de dados. Use
TTLpara manter dados em cache atualizados. - Particionamento: Divida tabelas grandes em partes menores ou sincronize dados entre plataformas (horizontal ou vertical) para melhorar o desempenho de consultas em conjuntos de dados massivos.
- Planos de Execução de Consulta: Analise planos de execução para identificar gargalos como varreduras sequenciais ou derramamentos de disco. Ajuste índices e estruturas de consulta de acordo.
Otimização de Latência de Consultas de Banco de Dados: 5 Técnicas Principais Comparadas
Por Que Minhas Consultas de Banco de Dados Estão Rodando Tão Devagar? - Next LVL Programming
1. Use Indexação de Banco de Dados
Pense em índices de banco de dados como o índice no final de um livro—eles funcionam como atalhos, apontando diretamente para as linhas que você precisa em uma tabela. Isso evita que o mecanismo de banco de dados faça a varredura de cada linha, tornando a recuperação de dados muito mais rápida. A maioria dos índices depende de uma estrutura de árvore B+, que é projetada para buscas rápidas baseadas em chaves. Configurar indexação adequada é uma etapa fundamental para otimizar suas consultas de banco de dados, especialmente ao avaliar opções de integração de banco de dados para seu aplicativo.
Concentre-se na indexação de colunas que são comumente usadas em WHERE, JOIN, e ORDER BY cláusulas—isso pode levar a melhorias notáveis no desempenho de consultas. Por exemplo, um índice abrangente pode buscar todas as colunas necessárias diretamente, reduzindo operações de entrada/saída desnecessárias.
Para consultas mais simples, índices de coluna única geralmente resolvem o problema. No entanto, para consultas com várias condições, índices compostos são o caminho a seguir. Ao criar índices compostos, organize as colunas estrategicamente: comece com filtros de igualdade, siga com filtros de intervalo e, em seguida, considere a distinção de coluna.
Embora os índices acelerem SELECT operações, eles têm uma desvantagem—podem desacelerar operações de escrita como INSERT, UPDATE, e DELETE. Para evitar sobrecarga desnecessária, fique atento a como seus índices estão sendo usados e remova aqueles que não agregam valor.
"Um erro de design comum é criar muitos índices especulativamente para 'dar ao otimizador opções'. A sobre-indexação resultante desacelera modificações de dados e pode causar problemas de concorrência." - Guia de Design de Índices do Microsoft SQL Server
Práticas Recomendadas de Indexação
Ao implementar índices, considere estas diretrizes:
- Chaves primárias são indexadas automaticamente na maioria dos sistemas de banco de dados
- Chaves estrangeiras usadas em junções se beneficiam significativamente de indexação
- Colunas com alta cardinalidade (muitos valores únicos) são melhores candidatas a índice do que colunas com poucos valores distintos
- Audite regularmente seus índices para identificar os não utilizados que apenas adicionam sobrecarga de escrita
Adalo é um construtor de aplicativos sem código para aplicativos web e aplicativos iOS e Android nativos orientados por banco de dados—uma versão em todas as três plataformas, publicada na Apple App Store e Google Play. Construtores de aplicativos modernos com IA como Adalo lidam com muita dessa complexidade automaticamente. Com a reformulação de infraestrutura de 2026 da plataforma, operações de banco de dados são executadas 3-4x mais rápida do que antes, e o sistema dimensiona a infraestrutura com as necessidades do aplicativo—o que significa que não há limite de registros nos planos pagos.
2. Escrever Consultas Mais Eficientes
A forma como você estrutura uma consulta pode fazer ou desfazer seu desempenho. Para começar, evite usar SELECT *. Em vez disso, especifique apenas as colunas que você realmente precisa. Por exemplo, se você está trabalhando com um banco de dados de clientes e precisa apenas do ID, nome e e-mail, solicite apenas esses três campos. Puxar colunas desnecessárias desperdiça memória e largura de banda.
A estrutura da consulta é tão importante quanto a indexação. Usar busca de entidade completa em ORMs (Mapeadores Objeto-Relacional) pode adicionar sobrecarga significativa. Um teste revelou que mudar para consultas sem rastreamento reduziu o tempo de execução de 1.414,7 microssegundos para 993,3 microssegundos e reduziu o uso de memória de 380,11 KB para 232,89 KB. Para evitar essa sobrecarga, use projeções em seu ORM—métodos como .Select() em EF Core ou .values() em Django—para recuperar apenas os campos necessários.
Otimizando Condições WHERE
Ao otimizar condições WHERE, tenha cuidado com a forma como você as escreve. Funções em colunas, como WHERE YEAR(hire_date) = 2020, impedem que os índices sejam usados efetivamente. Em vez disso, use condições baseadas em intervalo, como WHERE hire_date >= '2020-01-01' AND hire_date < '2021-01-01'. Essa abordagem mantém "SARG-ability" (capacidade de Argumento de Busca), permitindo que a consulta aproveite os índices. Da mesma forma, evite padrões com wildcards iniciais em LIKE consultas, pois esses forçam verificações de tabela completa.
O fator principal que decide se uma consulta é executada rapidamente ou não é se ela utilizará adequadamente os índices quando apropriado.
– Documentação da Microsoft
Reduzindo Junções e Subconsultas
Reduza o uso de junções e subconsultas desnecessárias. Subconsultas correlacionadas—aquelas que dependem da consulta externa—são particularmente problemáticas, pois são executadas uma vez para cada linha no conjunto de resultados. Em vez disso, substitua-as por junções padrão sempre que possível. Se você está verificando a existência de dados, use EXISTS em vez de IN. O EXISTS cláusula para de processar assim que encontra uma correspondência, tornando muito mais eficiente.
Como Mike Payne, um especialista em banco de dados, coloca: "Otimizar essas consultas é a coisa mais impactante que você pode fazer para melhorar a velocidade e escalabilidade do seu banco de dados".
Ada, o construtor de IA do Adalo, permite descrever o que você quer e gera seu app. Magic Start cria fundações completas de app a partir de uma descrição, enquanto Magic Add adiciona recursos através de linguagem natural.
Para aqueles que criam aplicativos sem escrever SQL diretamente, a interface visual do Adalo abstrai essas otimizações. Os recursos assistidos por IA da plataforma, como Magic Add permitem que você descreva quais dados precisa em linguagem natural, e o sistema gera consultas eficientes automaticamente. Isso é particularmente valioso para criadores não-técnicos que desejam desempenho sem se aprofundarem na otimização de consultas.
3. Armazenar em Cache Consultas Frequentemente Usadas
O cache é como dar um impulso de memória ao seu aplicativo. Em vez de consultar repetidamente o banco de dados, os dados frequentemente acessados são armazenados em memória, reduzindo o tempo necessário para recuperar informações. Isso evita os atrasos que vêm com o acesso ao disco, que—mesmo no seu melhor—pode levar milissegundos de dois dígitos.
Duas ferramentas populares para cache são Redis e Memcached. Redis se destaca pela sua capacidade de lidar com estruturas de dados complexas e sua opção de persistência em disco. Por outro lado, Memcached é mais simples e leve, projetado puramente para cache de alta velocidade. Para lhe dar uma ideia de seu poder, um único nó de cache em memória pode processar centenas de milhares de requisições por segundo.
Padrão Cache-Aside
O método de cache mais comum é cache-aside, também chamado de carregamento preguiçoso. Veja como funciona: o aplicativo verifica o cache primeiro. Se os dados não estiverem lá (um "miss"), ele consulta o banco de dados, recupera os dados e depois atualiza o cache. Este método é particularmente eficaz em cenários com muita leitura, onde os dados são lidos pelo menos 10 vezes mais frequentemente do que são escritos. Ao combinar essa estratégia com as técnicas de otimização de consulta anteriores, você pode reduzir significativamente a carga no seu banco de dados.
Para evitar que dados desatualizados fiquem pendentes, sempre defina um TTL (tempo de vida útil) para seus dados em cache. Se você está trabalhando com Redis, considere usar Hashes para armazenar linhas de banco de dados. Essa abordagem permite que você atualize campos individuais sem precisar processar um blob JSON inteiro. Além disso, fique de olho na sua taxa de acerto de cache—uma taxa baixa significa que seu cache não está sendo usado efetivamente, o que desperdiça memória sem aliviar a carga do banco de dados.
"A velocidade e a taxa de transferência do seu banco de dados podem ser o fator mais impactante para o desempenho geral da aplicação." – AWS
Quando Implementar Cache
Nem todo aplicativo precisa de uma camada de cache dedicada. Considere implementar cache quando:
- As consultas de banco de dados são consistentemente lentas apesar da otimização
- Os mesmos dados são solicitados repetidamente por múltiplos usuários
- Seu aplicativo experimenta picos de tráfego que sobrecarregam o banco de dados
- As operações de leitura superam significativamente as operações de escrita
A infraestrutura modular do Adalo gerencia o cache no nível da plataforma, o que significa que os aplicativos criados na plataforma se beneficiam da recuperação de dados otimizada sem configuração manual de cache. O sistema processa 20 milhões+ solicitações de dados diariamente com 99%+ de disponibilidade, demonstrando a eficácia de suas otimizações de desempenho integradas.
4. Particionar Grandes Conjuntos de Dados
Quando as tabelas crescem para milhões de linhas, até mesmo as consultas melhor indexadas podem começar a ficar lentas. Particionamento oferece uma forma de lidar com isso dividindo tabelas grandes em pedaços menores e mais gerenciáveis—chamados de partições—enquanto ainda as trata como uma única tabela lógica. Isso permite que o mecanismo de banco de dados use eliminação de partição, que pula partições irrelevantes durante uma consulta, reduzindo significativamente a quantidade de dados que ela precisa verificar. A chave é escolher o método certo para dividir seus dados a fim de garantir uma verificação eficiente.
Particionamento Horizontal vs. Vertical
Existem duas formas principais de particionar dados: particionamento horizontal e particionamento vertical.
- Particionamento Horizontal divide a tabela por linhas, geralmente com base em uma coluna específica como data ou região. Por exemplo, você poderia dividir uma tabela de vendas em pedaços mensais. Esse método funciona particularmente bem para dados de série temporal ou cenários onde consultas frequentemente filtram por um intervalo específico.
- Particionamento Vertical, por outro lado, separa colunas. É ideal para tabelas largas com muitos campos, especialmente se apenas algumas colunas são acessadas regularmente. Por exemplo, você poderia descarregar BLOBs grandes ou campos raramente usados em tabelas separadas.
Aqui está um exemplo do mundo real: particionar uma tabela de pedidos Airtable com 5.000.000 linhas por mês reduziu o tempo de consulta de 23ms para apenas 1ms. Mecanismos de banco de dados modernos como SQL Server podem lidar com até 15.000 partições por tabela. No entanto, é importante não exagerar—excesso de particionamento pode levar ao aumento do uso de memória e prejudicar o desempenho se as consultas acabarem verificando múltiplas partições.
| Tipo de Particionamento | Método | Melhor Para |
|---|---|---|
| Horizontal | Divide linhas (p.ex., por data ou intervalo de ID) | Grandes conjuntos de dados com consultas baseadas em intervalo |
| Vertical | Divide colunas (p.ex., separando BLOBs de campos frequentemente acessados) | Tabelas largas onde apenas algumas colunas são consultadas regularmente |
Escolhendo a Chave de Partição Correta
Para fazer o particionamento funcionar efetivamente, escolha uma coluna que seja frequentemente usada em cláusulas WHERE. Isso garante que o banco de dados possa aproveitar ao máximo a eliminação de partição. Além disso, alinhe seus índices com o esquema de particionamento para melhorar tarefas de manutenção. O particionamento é especialmente adequado para cargas de trabalho OLAP que envolvem verificações grandes, em vez de sistemas OLTP onde as consultas normalmente buscam linhas individuais.
Para construtores de aplicativos trabalhando com grandes conjuntos de dados, a infraestrutura Adalo agora escala com as necessidades do aplicativo—não há limite superior de registros de banco de dados para planos pagos. Com os relacionamentos de dados corretos, aplicativos construídos na plataforma podem escalar além de 1 milhão de usuários ativos mensais. Isso elimina a necessidade de estratégias de particionamento manual que outras plataformas com limites de registros exigem.
5. Revisar Planos de Execução de Consulta
Depois de abordar indexação e refatoração de consulta, aprofundar-se em planos de execução pode fornecer informações mais profundas sobre o desempenho da consulta. Até mesmo consultas bem otimizadas podem encontrar gargalos inesperados, e os planos de execução ajudam a descobrir como o banco de dados processa uma consulta. Eles detalham coisas como uso de índice, métodos de junção e operações de classificação.
Usando Ferramentas EXPLAIN e Plano de Execução
Em PostgreSQL, ferramentas como EXPLAIN e EXPLAIN ANALYZE são inestimáveis. EXPLAIN fornece custos estimados, enquanto EXPLAIN ANALYZE adiciona métricas de desempenho reais, como contagens de linhas e tempos de execução. Ao compará-las, você pode detectar discrepâncias que podem apontar para estatísticas desatualizadas ou indexação subótima. Da mesma forma, os planos de execução reais do SQL Server no Management Studio oferecem informações comparáveis. Essas ferramentas ajudam a identificar ineficiências que podem não ser óbvias por meio de outras técnicas de otimização.
O que Procurar
Ao analisar um plano de execução, preste atenção a padrões como "Verificação Sequencial" em tabelas grandes. Isso geralmente sugere que adicionar um índice pode melhorar o desempenho. Também procure condições de filtro que descartam a maioria das linhas após a verificação, pois estas podem se beneficiar da conversão para uma operação "Condição de Índice". Outro sinal de alerta é a classificação ou operações de hash derramando para disco, o que pode aumentar significativamente a latência da consulta. Comparar tempo de CPU com tempo decorrido também pode revelar se sua consulta é restrita pelo uso de CPU ou esperando operações de E/S.
Se um único operador, como "Classificação" ou "Junção de Hash", representar 90% do custo da consulta, é um alvo claro para otimização. Você também pode experimentar desabilitar temporariamente certas opções do planejador para testar estratégias de junção alternativas e ver se elas têm melhor desempenho na prática. Fique atento a avisos sobre conversões de tipo de dados implícitas, pois elas podem forçar o mecanismo a processar cada linha individualmente, prejudicando a eficiência do índice.
Análise de Desempenho Automatizada
Para quem prefere não analisar manualmente planos de execução, Adalo oferece X-Ray—um recurso de IA que identifica problemas de desempenho antes de afetar os usuários. Essa abordagem proativa para monitoramento de desempenho significa que você pode detectar e corrigir gargalos sem se aprofundar em integrações de banco de dados. O recurso destaca possíveis preocupações com escalabilidade e sugere otimizações, o que é particularmente valioso para construtores não técnicos escalando seus aplicativos.
Comparando Abordagens de Banco de Dados para Construtores de Aplicativos
Ao escolher uma plataforma de construção de aplicativos, o desempenho do banco de dados e a escalabilidade devem ser considerações principais. Diferentes plataformas lidam com armazenamento de dados e otimização de consulta de formas fundamentalmente diferentes.
| Plataforma | Abordagem de Banco de Dados | Limites de registros | Preço Inicial |
|---|---|---|---|
| Adalo | Incorporado + conexões externas | Ilimitado em planos pagos | $36/mês |
| Bubble | Incorporado com Unidades de Carga de Trabalho | Limitado por cálculos de Carga de Trabalho | $69/mês |
| Glide | Baseado em planilha | Limitado, cobranças adicionais se aplicam | $60/mês |
| FlutterFlow | Apenas externo (gerenciado pelo usuário) | Depende de provedor externo | $70/mês + custos de banco de dados |
Bubble oferece mais opções de personalização, mas essa flexibilidade frequentemente resulta em aplicativos mais lentos que sofrem sob aumento de carga. Muitos usuários do Bubble acabam contratando especialistas para otimizar seus aplicativos — reclamações de milhões de MAU são normalmente apenas alcançáveis com ajuda profissional. A solução de aplicativo móvel do Bubble também é um wrapper para o aplicativo web, introduzindo possíveis desafios em escala.
FlutterFlow é tecnicamente "low-code" em vez de "no-code" e se destina a usuários técnicos. Os usuários devem configurar e gerenciar seu próprio banco de dados externo, o que requer complexidade de aprendizado significativa. Qualquer coisa menos que a configuração ideal pode criar problemas de escala, razão pela qual o ecossistema FlutterFlow é rico em especialistas pagos.
Glide se destaca em aplicativos baseados em planilhas, mas cria aplicativos genéricos e simplistas com liberdade criativa limitada. Não suporta publicação na Apple App Store ou Google Play Store, limitando as opções de distribuição.
Conclusão
Reduzir a latência de consultas de banco de dados é tudo sobre melhorar a velocidade e garantir escalabilidade. Técnicas como indexação, escrita de consultas eficientes, cache, particionamento e revisão de planos de execução podem transformar consultas lentas de 30 segundos em respostas muito rápidas, sub-segundo.
Mas os benefícios vão além apenas de velocidade. Consultas simplificadas significam que menos recursos do servidor são consumidos, o que pode reduzir custos mensais e garantir uma experiência mais suave conforme sua base de usuários cresce. Consultas eficientes também ajudam a reduzir a carga do servidor e evitar atingir limites de taxa de API, como Airtablerestrição de 5 solicitações por segundo.
Adalo, um construtor de aplicativos alimentado por IA, simplifica essas otimizações através de sua interface visual e backend integrado. Para aplicativos com conjuntos de dados menores, o banco de dados integrado do Adalo oferece zero latência de API com desempenho rápido. Precisa dimensionar ou trabalhar de forma colaborativa? Você pode se conectar a bancos de dados externos como Airtable, PostgreSQL ou MS SQL Server usando Coleções Externas, disponível no plano Professional a partir de $36 por mês. Essa flexibilidade permite que você comece com uma configuração simples e dimensione conforme necessário sem reformular seu aplicativo.
Para começar, concentre-se em analisar suas consultas mais lentas com ferramentas como EXPLAIN e aborde os gargalos mais urgentes primeiro. Seja adicionando um índice ou configurando uma camada de cache, cada melhoria se baseia na anterior. Como Mike Payne de Paessler observa com sabedoria:
Você não pode otimizar o que não consegue ver. O monitoramento de banco de dados ilumina exatamente onde residem os problemas de desempenho.
Depois de identificar os pontos problemáticos, as correções são frequentemente diretas e entregam resultados imediatos.
Postagens de Blog Relacionadas
- 8 Maneiras de Otimizar o Desempenho do Seu Aplicativo Sem Código
- Como Criar um Aplicativo Usando Dados IBM DB2
- 5 Métricas para Acompanhar o Desempenho de Aplicativos Sem Código
- Escalando aplicativos sem código para grandes conjuntos de dados
Perguntas Frequentes
Por que escolher Adalo em vez de outras soluções de construção de aplicativos?
Adalo é um construtor de apps com tecnologia IA que cria apps nativos verdadeiros para iOS e Android. Diferentemente de wrappers web, ele compila para código nativo e publica diretamente em ambas a Apple App Store e Google Play Store a partir de um único código-base—a parte mais difícil do lançamento de um app é feita automaticamente.
Qual é a forma mais rápida de construir e publicar um aplicativo na App Store?
A interface de arrastar e soltar do Adalo combinada com construção assistida por IA através do Magic Start e Magic Add permite que você crie aplicativos completos em horas em vez de semanas. A plataforma lida com todo o processo de envio para a App Store, removendo as barreiras técnicas que tipicamente atrasam os lançamentos de aplicativos.
Posso otimizar facilmente consultas de banco de dados no meu aplicativo?
Sim, com a interface visual do Adalo e backend integrado, você pode otimizar o desempenho do banco de dados sem escrever SQL. Para aplicativos com conjuntos de dados menores, o banco de dados integrado do Adalo oferece zero latência de API, e você pode se conectar a bancos de dados externos como PostgreSQL ou Airtable para conjuntos de dados maiores usando Coleções Externas.
Qual é a forma mais impactante de reduzir a latência de consultas de banco de dados?
A indexação adequada de banco de dados é frequentemente o primeiro passo mais impactante, pois os índices atuam como atalhos que apontam diretamente para as linhas necessárias em vez de varrer tabelas inteiras. Concentre-se em indexar colunas comumente usadas nas cláusulas WHERE, JOIN e ORDER BY para os melhores ganhos de desempenho.
Quando devo usar cache versus particionamento para conjuntos de dados grandes?
Use cache quando você tem dados acessados frequentemente que não mudam frequentemente — ferramentas como Redis ou Memcached podem lidar com centenas de milhares de solicitações por segundo. Use particionamento quando suas tabelas crescem para milhões de linhas e consultas filtram por intervalos específicos como datas, pois permite que o banco de dados pule dados irrelevantes completamente.
Como identifico quais consultas estão causando problemas de desempenho?
Use ferramentas de plano de execução de consulta como EXPLAIN em PostgreSQL ou planos de execução real em SQL Server para ver exatamente como o banco de dados processa suas consultas. Adalo também oferece X-Ray, um recurso de IA que identifica problemas de desempenho antes que afetem os usuários.
Por que devo evitar usar SELECT * em minhas consultas de banco de dados?
Usar SELECT * recupera todas as colunas de uma tabela, desperdiçando memória e largura de banda quando você só precisa de campos específicos. Especificar apenas as colunas necessárias pode reduzir significativamente o tempo de execução e o uso de memória — benchmarks mostram que a mudança para consultas direcionadas pode reduzir o consumo de memória em quase 40%.
O que é mais acessível, Adalo ou Bubble?
Adalo começa em $36/mês com uso ilimitado e sem limites de registros em planos pagos. Bubble começa em $69/mês com cobranças de Workload Unit baseadas em uso e limites de registros. Adalo também inclui atualizações ilimitadas de aplicativos uma vez publicados, enquanto Bubble tem restrições de republicação.
Adalo é melhor que FlutterFlow para aplicativos móveis?
Para usuários não técnicos, sim. FlutterFlow é "low-code" direcionado a usuários técnicos que devem configurar e gerenciar seu próprio banco de dados externo. Adalo inclui um banco de dados integrado sem limites de registros em planos pagos, e seu construtor visual é descrito como "fácil quanto PowerPoint" enquanto ainda produz aplicativos nativos para iOS e Android.
O Adalo tem limites de registros de banco de dados?
Não. Os planos pagos possuem registros de banco de dados ilimitados sem limites. Com as configurações corretas de relacionamento de dados, aplicativos Adalo podem dimensionar para além de 1 milhão de usuários ativos mensais. A infraestrutura modular da plataforma dimensiona automaticamente com as necessidades do seu aplicativo.
Construa seu aplicativo rapidamente com um de nossos modelos de aplicativo pré-prontos
Comece a Construir sem códigoConteúdo Relacionado

Melhorando o Tempo de Resposta da API com Bancos de Dados Legados
Acelere APIs usando bancos de dados legados com ajuste de consultas, indexação, cache, pool de conexões e correções para consultas N+1 para reduzir latência

Resolvendo Problemas de Desempenho em APIs Legadas
Reduza a latência de APIs legadas com cache, ajuste de consultas, wrappers de API e migração gradual de microsserviços — vitórias práticas rápidas e soluções de longo prazo

Como IA e MicroAplicativos Estão Prestes a Mudar o Fluxo de Trabalho Corporativo
Microaplicativos alimentados por IA automatizam tarefas repetitivas, modernizam sistemas legados e habilitam compilações de aplicativos sem código para acelerar fluxos de trabalho, cortar custos e

Futuro do SaaS: Automação de Fluxo de Trabalho Alimentada por IA
Como o SaaS orientado por IA usa agentes autônomos, fluxos de trabalho em linguagem natural e otimização preditiva para acelerar processos, cortar custos e integrar