
Aplicativos modernos devem funcionar perfeitamente em plataformas como iOS, Android e web. Mas sincronizar dados entre esses sistemas é complicado. Aqui está o porquê:
Plataformas como Adalo, um construtor de aplicativos sem código para aplicativos web orientados a banco de dados e aplicativos iOS e Android nativos—uma versão em todas as três plataformas, publicada na Apple App Store e Google Play, ajuda a resolver esses desafios fornecendo gerenciamento de dados unificado em dispositivos a partir de um único ambiente de desenvolvimento.
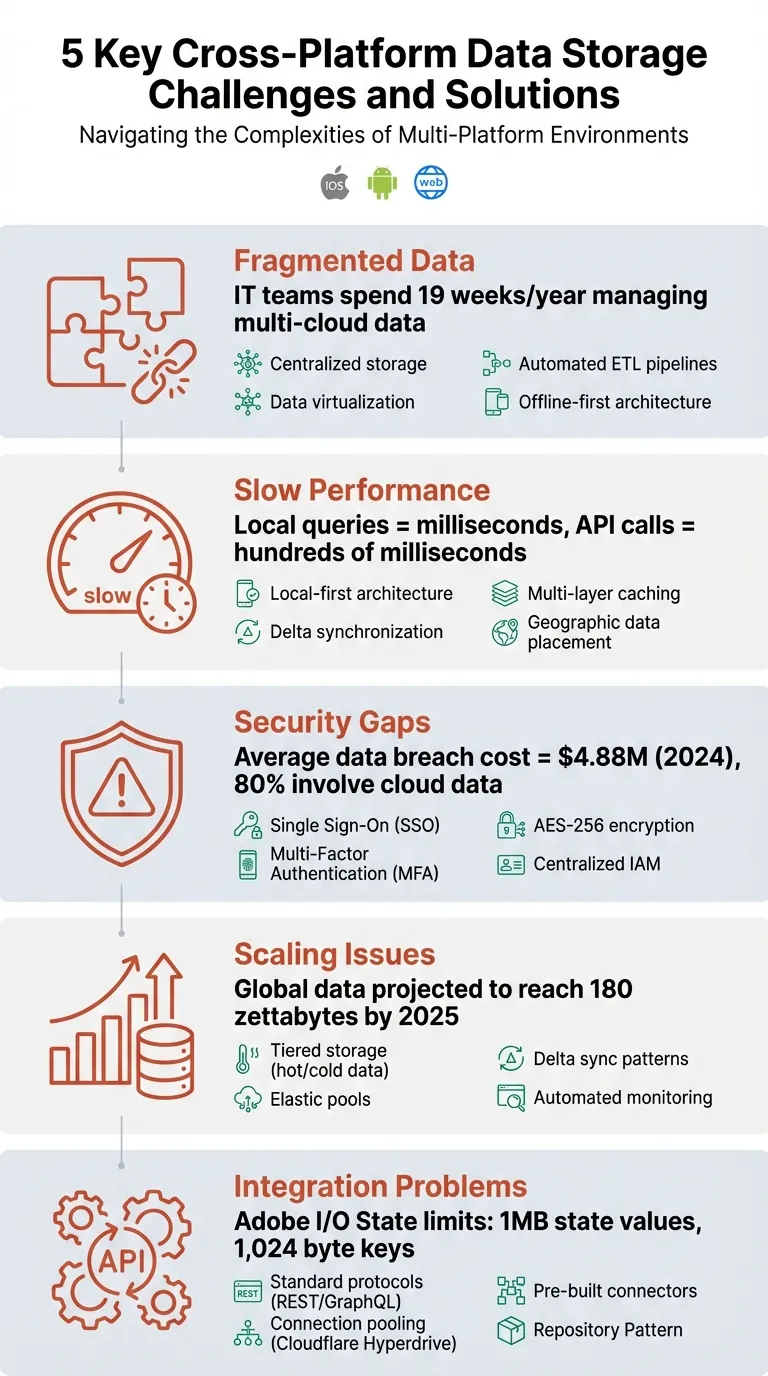
- Dados Fragmentados: Sistemas desconectados criam silos, dificultando a sincronização de informações.
- Desempenho Lento: Atrasos de rede e métodos de sincronização ineficientes frustram os usuários.
- Lacunas de Segurança: Medidas inconsistentes em plataformas aumentam riscos.
- Problemas de Escalabilidade: Demandas crescentes de dados podem sobrecarregar a infraestrutura.
- Problemas de Integração: Problemas de compatibilidade entre sistemas retardam o desenvolvimento.
Soluções incluem arquiteturas local-first, padrões de sincronização delta, protocolos de segurança unificados e estratégias de armazenamento escaláveis. Essas abordagens garantem sincronizações mais rápidas, melhor segurança e operações multiplataforma mais suaves.
5 Principais Desafios e Soluções de Armazenamento de Dados Multiplataforma
Desafio 1: Dados Fragmentados e Sistemas Desconectados
O Que São Silos de Dados
Dados fragmentados em plataformas criam um grande obstáculo para sincronização perfeita. Silos de dados surgem quando diferentes departamentos ou plataformas armazenam informações sem vinculá-las. Por exemplo, sua equipe de vendas pode depender de um banco de dados, seu aplicativo móvel de outro e sua plataforma web de um terceiro - forçando reconciliação manual para alinhar os dados.
Sistemas legados frequentemente falham em se integrar com ferramentas modernas baseadas em nuvem, deixando para trás pools isolados de dados. Fusões podem agravar o problema, reunindo bancos de dados com estruturas incompatíveis. Enquanto isso, departamentos gerenciando seus dados independentemente amplificam a fragmentação. Em indústrias como saúde, esses dados desconectados podem custar dezenas a centenas de bilhões de dólares anualmente, enquanto equipes de TI gastam uma média de 19 semanas por ano gerenciando dados em múltiplos ambientes de nuvem pública.
Soluções: Conectando Seus Dados
Quebrar esses silos começa com a integração de dados de várias fontes em um sistema unificado. Uma abordagem eficaz é adotar arquiteturas de armazenamento centralizado, que criam uma única fonte da verdade. Data lakes são ideais para consolidar dados brutos e não estruturados de múltiplas fontes, enquanto data warehouses são mais adequados para gerenciar dados estruturados usados em análises específicas. Para maior flexibilidade, data lakehouses combinam os pontos fortes de ambos, permitindo gerenciamento de dados estruturados e não estruturados em um único sistema.
Outra solução é virtualização de dados. Ferramentas como Denodo e Dados de hardware Cisco permitem que você acesse uma visão unificada de dados em plataformas como AWS, Azure, e Serviços de IA do Google Cloud sem mover fisicamente os dados. Isso é particularmente útil para análise em tempo real quando manter dados em sua localização original é necessário.
Para organizações prontas para consolidar, pipelines de ETL automatizados simplificam o processo. Ferramentas como Talend ou Stitch Data podem mover e transformar dados de sistemas diferentes em um warehouse centralizado. Armazenar dados em formatos interoperáveis como Apache Parquet ou Avro garante compatibilidade com ferramentas de análise e plataformas em nuvem.
Aplicativos multiplataforma podem se beneficiar significativamente de arquiteturas local-first, que armazenam dados em cache localmente e sincronizam com a nuvem quando a conectividade é restaurada. Isso garante que os usuários tenham acesso a informações mesmo em condições de rede precárias, melhorando a sincronização de dados em plataformas iOS, Android e web simultaneamente.
Desafio 2: Desempenho Lento e Atrasos
O Que Causa Atrasos Multiplataforma
Quando os sistemas são fragmentados, garantir transferências rápidas de dados torna-se essencial para evitar desempenho multiplataforma lento. Um grande culpado atrás de atrasos é modelos de dados dependentes de servidor, que exigem que os aplicativos aguardem respostas do servidor antes de mostrar informações. Enquanto consultas locais podem ser concluídas em apenas alguns milissegundos, chamadas de rede podem levar centenas - especialmente quando os servidores estão localizados longe dos usuários ou quando as condições de rede são ruins. O arquiteto móvel Sudhir Mangla descreve esse cenário frustrante como Lie-Fi - situações onde dispositivos indicam um sinal forte mas sofrem com baixa taxa de transferência, picos de latência imprevisíveis ou solicitações perdidas.
Métodos de sincronização ineficientes também desempenham um papel importante. Abordagens de sincronização completa, por exemplo, geralmente descartam dados locais para recarregar conjuntos de dados inteiros, desperdiçando tempo e recursos. Da mesma forma, limites de taxa de API de terceiros podem forçar múltiplos ciclos para importar grandes conjuntos de dados, desacelerando ainda mais as coisas.
"Mesmo quando a rede é forte, buscar dados localmente é sempre mais rápido do que uma viagem de ida e volta ao servidor. Uma consulta em um banco de dados no dispositivo pode retornar resultados em milissegundos; uma chamada de API pode levar centenas." - Sudhir Mangla, Mobile Architect
Offline-first é, portanto, não apenas uma estratégia de resiliência - é uma estratégia de desempenho.
Esses desafios destacam a necessidade de repensar como os dados são transferidos e gerenciados.
Soluções: Transferência de Dados Mais Rápida
Uma combinação de arquitetura local-first e sincronização delta pode melhorar significativamente o desempenho. Ao usar um banco de dados no dispositivo - como Room, Realm, ou SQLite - como o armazenamento de dados principal, os aplicativos podem lidar com interações de UI instantaneamente. Um mecanismo de sincronização em segundo plano pode gerenciar atualizações de dados, trocando apenas os registros que foram alterados usando tokens de sincronização orientados pelo servidor para evitar problemas de desvio de relógio.
Para melhorar ainda mais a velocidade, implemente cache em múltiplas camadas para respostas de API, consultas de banco de dados e ativos estáticos, garantindo que dados frequentemente acessados sejam recuperados rapidamente. Coloque armazenamentos de dados na mesma região geográfica dos componentes da sua aplicação para reduzir a latência e evitar custos adicionais de largura de banda entre regiões. Gerenciadores de tarefas em segundo plano podem lidar com processos de sincronização sem interromper as interações do usuário, enquanto atualizações otimistas permitem que a UI reflita as mudanças imediatamente, sincronizando em segundo plano para finalizar as atualizações.
Essas estratégias não apenas abordam atrasos, mas também criam uma experiência do usuário mais suave e responsiva.
Desafio 3: Problemas de Segurança e Controle de Acesso
Riscos de Segurança Inconsistente
Quando as práticas de segurança diferem entre plataformas como iOS, Android e web, vulnerabilidades surgem. Em 2026, o custo médio de uma violação de dados atingiu US$ 4,88 milhões, com aproximadamente 80% das violações vinculadas a dados armazenados em nuvem. Isso ressalta os sérios riscos comerciais de medidas de segurança inconsistentes.
Uma preocupação importante é vazamento de dados entre inquilinos em infraestruturas compartilhadas. Sem autenticação e autorização fortes em vigor, é possível que um inquilino acesse inadvertidamente os dados de outro em bancos de dados compartilhados ou contêineres de blob. Agravando o problema, os provedores de nuvem geralmente usam configurações padrão e protocolos de criptografia variados, criando pontos fracos que os invasores podem explorar. Processos manuais, como rastreamento de alterações de esquema ou aplicação de patches em vários bancos de dados, aumentam ainda mais as chances de erro humano e lacunas de segurança.
Outro desafio está em implementar controles granulares como segurança em nível de linha. Sem design e testes adequados, esses controles podem deixar lacunas exploráveis. Em sistemas de replicação assíncrona, atualizações simultâneas em locais podem levar a estados de dados inconsistentes, potencialmente contornando restrições de segurança se a resolução de conflitos não for tratada adequadamente.
A solução? Uma estratégia de segurança unificada que funcione perfeitamente em todas as plataformas.
Soluções: Sistemas de Segurança Unificados
Para resolver esses desafios, uma abordagem consolidada de segurança é essencial. Comece com Logon Único (SSO) o uso de protocolos como OAuth 2.0 ou SAML. Isso garante políticas de segurança consistentes em todas as plataformas - seja iOS, Android ou web. Combine isso com Gerenciamento de Identidade e Acesso (IAM) centralizado para aplicar o Princípio do Menor Privilégio, limitando o acesso do usuário apenas ao necessário para suas funções.
Autenticação Multifator (MFA) é outra camada crítica de defesa. Com phishing e credenciais roubadas sendo os principais métodos de ataque em 2026, a MFA reduz significativamente o risco. Combine isso com protocolos de criptografia padronizados, como AES-256 para dados em repouso e TLS para dados em trânsito, para estabelecer proteção robusta em toda a sua infraestrutura.
Aqui está como uma abordagem unificada simplifica a segurança:
| Recurso de Segurança | Desafio Específico da Plataforma | Benefício Unificado |
|---|---|---|
| Autenticação | APIs biométricas diferentes (FaceID vs. Android Biometrics) | MFA/SSO centralizado garante uma experiência de login consistente |
| Controle de Acesso | Manipulação inconsistente de permissões entre versões do SO | Controle de Acesso Baseado em Função (RBAC) padroniza permissões em dispositivos |
| Gerenciamento de Sessão | Armazenamento de token variado (Keychain vs. Keystore) | Gerenciamento de token unificado simplifica a lógica de expiração e atualização |
| Armazenamento de Dados | Diferentes padrões de criptografia por plataforma | Criptografia padronizada (AES-256) protege dados em todas as plataformas |
Para maior segurança, considere criptografia em nível de inquilino usando ferramentas como "Always Encrypted" ou chaves gerenciadas pelo cliente (CMK). Essas garantem que os dados permaneçam protegidos mesmo em ambientes de armazenamento compartilhado. O padrão Valet Key é outro método eficaz, oferecendo acesso seguro e limitado no tempo aos recursos de armazenamento entre plataformas. Além disso, armazenar credenciais confidenciais e chaves de API em ferramentas dedicadas de gerenciamento de segredos - em vez de codificá-las - fornece uma camada extra de proteção.
A automação é fundamental para reduzir erros humanos. Automatize alterações de esquema, configurações de segurança e auditorias regulares de IAM para manter sua postura de segurança forte. Para comunicação entre plataformas, use TLS mútuo (mTLS) certificados para autenticar serviços e garantir transferência segura de dados entre ambientes de nuvem.
Desafio 4: Dimensionamento e Gerenciamento de Custos
Como o Crescimento de Dados Afeta a Infraestrutura
Os dados estão crescendo em um ritmo impressionante. Até 2026, os dados globais devem atingir 180 zettabytes, com muitos sistemas modernos gerando terabytes - ou até petabytes - todos os dias. Para aplicativos entre plataformas, esse aumento de dados vem de duas fontes: os dados crescentes gerados por cliente e uma base de clientes em expansão constante.
Lidar com essa explosão de dados não é fácil. Bancos de dados tradicionais frequentemente têm dificuldade em acompanhar uma escala tão grande. Em configurações de infraestrutura compartilhada, o problema do "vizinho ruidoso" - onde o uso intensivo de um locatário prejudica o desempenho de todos os outros - pode complicar ainda mais as coisas. Quando você está gerenciando 50 locatários ou mais, a supervisão manual se torna praticamente impossível, tornando as ferramentas de dimensionamento automatizado uma necessidade.
Trate os dados como o ativo mais valioso de sua solução. Como um fornecedor independente de software (ISV), você é responsável por gerenciar os dados de seus clientes. Sua estratégia de design de dados e escolha de armazenamento de dados podem afetar significativamente seus clientes.
– Marco de Boa Arquitetura do Microsoft Azure
Sem um plano sólido, você corre o risco de fazer superprovisionamento - desperdiçando dinheiro em recursos não utilizados - ou subprovisionamento, o que leva a requisições limitadas e usuários frustrados. Em ambientes multilocatário, contas de armazenamento que excedem seus limites de operações por segundo podem começar a rejeitar requisições, interrompendo o serviço para todos os usuários.
Para abordar efetivamente esses desafios, é necessária uma abordagem estratégica que equilibre desempenho e eficiência de custos.
Soluções: Armazenamento em Camadas e Controle de Custos
Para lidar com volumes de dados crescentes sem estourar seu orçamento, você precisa de uma combinação de estratégias inteligentes. Baseando-se nas medidas de desempenho e segurança discutidas anteriormente, o controle de custos se torna a peça final para operações contínuas entre plataformas.
Comece alinhando sua abordagem de armazenamento com padrões de uso reais. Armazenamento em camadas é uma ótima maneira de otimizar custos. Os dados "quentes" acessados com frequência podem permanecer em SSDs de alto desempenho, enquanto dados menos usados são movidos para opções mais econômicas, como armazenamento de objetos ou camadas de arquivo. Este método reduz drasticamente as despesas mantendo a velocidade para usuários ativos.
Planejamento de capacidade é outro passo crítico. Usar um modelo de "dimensionamento em camisetas" - categorizando clientes como pequeno, médio ou grande - ajuda a prever necessidades de recursos e alinhá-las com estruturas de faturamento apropriadas. Combine isso com gerenciamento do ciclo de vida dos dados, que automatiza a retenção de dados. Por exemplo, bancos de dados como Azure Cosmos DB oferecem recursos de Time-to-Live (TTL) para deletar automaticamente registros desatualizados, mantendo seu banco de dados principal otimizado.
Para cargas de trabalho com picos imprevisíveis, pools elásticos e modelos de throughput compartilhado permitem que múltiplos bancos de dados compartilhem um único pool de recursos. Modelos serverless, que dimensionam automaticamente com base na demanda, são outra opção, embora possam se tornar menos econômicos conforme o uso aumenta.
Para reduzir ainda mais os custos em configurações multilocatário, adote padrões de sincronização delta. Eles reduzem a largura de banda e as demandas do servidor sincronizando apenas as alterações em vez de todo o conjunto de dados. Por exemplo, o banco de dados D1 SQL da Cloudflareusa bancos de dados menores de 10GB organizados por usuário ou locatário para dimensionar com eficiência.
O monitoramento também é fundamental. Fique atento à limitação acompanhando operações de armazenamento rejeitadas para garantir que contas compartilhadas permaneçam dentro de seus limites. Automatizar tarefas como reconstrução de índices e rebalanceamento de partições também pode reduzir a necessidade de intervenção manual, economizando tempo e dinheiro.
| Estratégia | Melhor Para | Impacto de Custos |
|---|---|---|
| Pools Elásticos | Bancos de dados pequeno/médios com picos de demanda variáveis | Alta eficiência; reduz custos de recursos ociosos |
| Serverless | Novos aplicativos ou cargas de trabalho imprevisíveis e com baixa frequência | Pagamento por uso; pode ficar custoso em escalas maiores |
| Armazenamento de Arquivo | Conformidade de longo prazo e dados históricos | Menor custo; tempos de recuperação mais lentos |
| Sincronização Delta | Aplicativos móveis/entre plataformas | Reduz despesas de largura de banda e servidor |
Desafio 5: Problemas de Integração e Compatibilidade
Barreiras Comuns de Integração
Conectar sistemas de armazenamento entre plataformas não é tão simples quanto parece. Um grande obstáculo é incompatibilidade de biblioteca, que frequentemente força desenvolvedores a manter bases de código separadas para aplicativos móveis e web. Mesmo quando sistemas compartilham a mesma estrutura de dados, inconsistências em como diferentes sistemas operacionais e navegadores lidam com JSON podem levar a comportamentos impredizíveis do aplicativo.
Outro desafio é latência de conexão, particularmente em ambientes sem servidor. Bancos de dados SQL tradicionais dependem de soquetes TCP, que requerem múltiplas viagens de ida e volta para estabelecer conexões seguras. Em configurações sem servidor ou de computação de borda, essas conexões devem ser restabelecidas a cada invocação, adicionando atrasos perceptíveis. Este problema é agravado ainda mais pela distância geográfica - servidores baseados nos EUA, por exemplo, podem introduzir atraso para usuários em outras partes do mundo.
Soluções de armazenamento nativas da nuvem trazem suas próprias limitações. Por exemplo, armazenamentos simples de chave-valor como Adobe I/O State carecem de recursos essenciais de consulta, como filtrar linhas, selecionar colunas específicas ou limitar resultados. Desenvolvedores acostumados com bancos de dados tradicionais frequentemente sentem falta dessas funcionalidades. Além disso, Adobe I/O State restringe valores de estado a 1MB e tamanhos de chave a 1.024 bytes, o que pode ser limitador para certos casos de uso. Esses desafios destacam a necessidade urgente de protocolos padronizados para simplificar a integração entre plataformas.
Soluções: Protocolos Padrão e Conectores Prontos
Protocolos padronizados e plataformas com conectores integrados oferecem uma forma prática de enfrentar desafios de integração. Ferramentas como Cloudflare Hyperdrive resolvem problemas de latência ao agrupar conexões de banco de dados globalmente, eliminando atrasos causados por apertos de mão TCP repetidos. Para sistemas sem conectores nativos, APIs REST ou interfaces GraphQL fornecem uma ponte, permitindo compatibilidade entre plataformas. Enquanto isso, ferramentas como Adobe I/O State oferecem abstrações JavaScript sobre bancos de dados distribuídos, permitindo que desenvolvedores gerenciem persistência de estado sem se aprofundar em configurações complexas de nuvem.
Plataformas como Adalo simplificam ainda mais a integração ao oferecer conectores pré-construídos para serviços populares de terceiros, incluindo Airtable, Google Sheets, MS SQL Server, e PostgreSQL. Essas integrações prontas reduzem a necessidade de codificação extensa de back-end. Para sistemas legados sem APIs, Adalo Blue aproveita DreamFactory para simplificar conexões.
Outra abordagem eficaz é o Padrão de Repositório, que cria um limite claro entre a camada de UI e armazenamento. Essa abstração oculta se os dados são armazenados localmente (por exemplo, SQLite ou Realm) ou remotamente via APIs de nuvem, tornando o código entre plataformas mais fácil de manter. Os desenvolvedores também podem usar extensões de arquivo específicas da plataforma como index.web.js e index.ios.js para garantir que o código correto seja executado em cada plataforma automaticamente. Para melhorar a segurança, sempre proteja credenciais sensíveis como chaves de API e senhas de banco de dados com segredos de ambiente. Ferramentas como segredos do Wrangler permitem que você injete com segurança essas credenciais em tempo de execução.
Aprenda a Criar Aplicativos Multiplataforma Capazes de Armazenamento de Dados Online-Offline em Menos de 30 Minutos
Como Implementar Essas Soluções
Enfrentar os desafios do armazenamento de dados entre plataformas requer uma abordagem bem pensada. Aqui está como você pode colocar essas soluções em prática.
Dividindo Grandes Migrações
Ao mover dados, fazê-lo passo a passo é a escolha mais inteligente. Em vez de deslocar tudo de uma vez, considere migração em fases - também chamada de migração em gotejamento. Este método transfere dados em pedaços menores, permitindo que os sistemas antigo e novo funcionem lado a lado. A vantagem? Tempo de inatividade mínimo e testes contínuos, tornando-o ideal para sistemas críticos. Por exemplo, uma empresa conseguiu fazer a transição de seu sistema de pagamentos em tempo real sem interrupções seguindo essa abordagem.
Outra opção é a estratégia de migração paralela, onde ambos os sistemas operam simultaneamente com sincronização em vigor. O tráfego é redirecionado para o novo sistema apenas após ser completamente testado e validado. Ambas as estratégias evitam os riscos de uma migração "big-bang", que poderia levar a tempo de inatividade prolongado ou falhas maiores se algo der errado.
Após completar a migração, o monitoramento contínuo é essencial para manter o desempenho e garantir a estabilidade.
Monitoramento e Melhoria de Sistemas de Dados
Assim que seu armazenamento entre plataformas estiver funcionando, ficar de olho no desempenho é imprescindível. Use métricas como bytes por segundo (B/s) ou transações por segundo (TPS) para rastrear o quão bem o sistema está funcionando. Até pequenas mudanças em consultas podem ter um efeito notável na velocidade, então avaliações regulares de desempenho são cruciais. O monitoramento de taxa de transferência ajuda a identificar gargalos antes que afetem os usuários.
"Toda vez que seu aplicativo consulta o banco de dados... o desempenho do aplicativo sofrerá. Portanto, é fundamental que você sempre mantenha o desempenho em mente ao construir." - Recursos do Adalo
Automatizar tarefas rotineiras pode economizar tempo e melhorar a saúde do sistema. Tarefas como reconstruir índices, rebalancear partições e monitorar o volume de dados devem ser automatizadas sempre que possível. Fique atento à limitação e ajuste o desempenho regularmente para manter tudo funcionando adequadamente.
Quando sua base de usuários e dados crescem, uma plataforma escalável torna-se essencial para manter o desempenho consistente.
Usando Plataformas Escaláveis
Uma plataforma construída em uma única base de código pode simplificar significativamente a manutenção entre plataformas. Adalo, por exemplo, usa uma arquitetura de base de código única que simplifica o desenvolvimento de aplicativos móveis e web. Atualizações feitas uma vez são aplicadas automaticamente em plataformas iOS, Android e web.
Esta abordagem unificada não apenas reduz a fragmentação, mas também acelera a implantação. As equipes podem lançar aplicativos prontos para produção em dias ou semanas, em comparação com os meses normalmente necessários para soluções personalizadas.
Conclusão
Gerenciar armazenamento de dados entre plataformas vem com uma série de desafios - sistemas fragmentados, diminuição de desempenho, vulnerabilidades de segurança e problemas de escalabilidade. Enfrentar essas demandas requer soluções unificadas que sejam bem planejadas, seguras e capazes de crescer com suas necessidades.
Líderes do setor consistentemente destacam a importância dos dados em qualquer solução:
Os dados são frequentemente considerados a parte mais valiosa de uma solução porque representam suas informações comerciais valiosas e de seus clientes.
– John Downs, Principal Software Engineer, Microsoft
Ao gerenciar operações para dezenas de locatários, a automação se torna uma ferramenta inegociável. Ela permite crescimento contínuo sem esbarrar em limites de capacidade. Como explorado neste artigo, o sucesso está em adotar uma estratégia unificada - aquela que integra desenvolvimento, implementação e segurança em um framework coeso. Trate seus dados como seu ativo mais crítico, aproveitando serviços gerenciados, metodologias padronizadas e arquiteturas de base de código única para reduzir riscos e manter desempenho consistente entre plataformas. Etapas como migrações em fases, monitoramento ativo e manutenção automatizada garantem uma base sólida para operações eficientes e escaláveis.
Postagens de Blog Relacionadas
- Sincronização Offline vs. Em Tempo Real: Gerenciando Conflitos de Dados
- Sincronização Orientada por Eventos para Aplicativos Offline-First
- Como Sincronizar Dados Entre Aplicativos Web e Móveis
- Sincronização de ERP em Tempo Real com Sistemas Legados
Perguntas Frequentes
Como uma arquitetura local-first melhora a sincronização de dados entre plataformas?
Uma arquitetura local-first concentra-se em armazenar e processar dados diretamente no dispositivo do usuário, oferecendo uma experiência contínua mesmo quando não há conexão com a internet. Essa abordagem garante que os usuários possam acessar e atualizar informações sem interrupções, tornando-a especialmente útil em áreas com conectividade de rede fraca ou não confiável. Além disso, ao lidar com a maioria das operações no dispositivo, os aplicativos se tornam mais responsivos, com atrasos reduzidos causados pela comunicação com o servidor.
Quando a conexão é restaurada, o sistema sincroniza automaticamente as alterações feitas localmente com bancos de dados remotos, mantendo os dados consistentes entre dispositivos e plataformas. Esse processo de sincronização geralmente inclui a detecção e resolução de conflitos para manter a precisão dos dados. Ao sincronizar apenas quando necessário, a arquitetura local-first conserva recursos de rede, alivia a demanda do servidor e escala efetivamente. Isso a torna uma escolha inteligente para aplicativos projetados para uso em múltiplos dispositivos, proporcionando uma experiência mais rápida e confiável em condições de rede menos que ideais.
Quais são as melhores formas de proteger dados em diferentes plataformas?
Proteger dados em diferentes plataformas exige uma mistura de estratégias para mantê-lo seguro e acessível. Um passo fundamental é criptografar dados em repouso e em trânsito. Isso garante que informações sensíveis permaneçam protegidas, especialmente quando estão sendo transferidas entre plataformas ou ambientes de nuvem.
Outra medida crítica é configurar controles de acesso fortes. Ferramentas como Logon Único (SSO) e permissões baseadas em função restringem o acesso apenas aos autorizados. Combine-as com protocolos de autenticação segura e sistemas de gerenciamento de identidade para adicionar uma camada extra de proteção.
Para aprimorar a segurança e o desempenho, refine como os dados são gerenciados. Simplifique consultas, use cache para reduzir tempos de carregamento e adote padrões de sincronização offline-first para garantir que os dados permaneçam consistentes mesmo em condições de rede não confiáveis. Essas etapas não apenas melhoram a experiência do usuário, mas também minimizam riscos potenciais vinculados a dados desatualizados ou não sincronizados. Juntas, essas estratégias criam um framework robusto para proteger dados em plataformas.
O que é armazenamento em camadas e como ele reduz custos no armazenamento de dados entre plataformas?
O armazenamento em camadas oferece uma forma inteligente de gerenciar dados entre plataformas, organizando-os com base na frequência com que são acessados. Dados que são acessados frequentemente são mantidos em armazenamento de alta velocidade e premium, enquanto dados menos usados são deslocados para opções mais lentas e econômicas.
Esse método equilibra desempenho e custo. Garante que tarefas críticas funcionem perfeitamente enquanto mantém despesas de armazenamento gerenciáveis. Ao combinar soluções de armazenamento com o uso de dados, as empresas podem economizar dinheiro sem comprometer eficiência ou potencial de crescimento.
Construa seu aplicativo rapidamente com um de nossos modelos de aplicativo pré-prontos
Comece a Construir sem códigoConteúdo Relacionado
Lista de verificação para testes de aplicativos entre plataformas
Lista de verificação para testes de aplicativos entre plataformas
Uma lista de verificação prática para testar aplicativos entre plataformas em iOS, Android, web e PWAs—cobre funcionalidade, UI/UX, desempenho, segurança, dispo
Melhor Construtor de Aplicativos IA Multiplataforma em 2026
Melhor Construtor de Aplicativos IA Multiplataforma em 2026
Compare os melhores construtores de aplicativos IA para multiplataforma em 2026. Dados independentes de 345 fontes públicas. Descubra quais plataformas são lançadas para iOS, Android e web a partir de um projeto.

Melhores Práticas para Implantação de Aplicativos Multiplataforma
Implante aplicativos em web, iOS e Android a partir de uma base de código: use CI/CD, testes entre plataformas e otimizações específicas da plataforma para economizar t

Guia completo para implantação de aplicativos entre plataformas
Crie, publique e mantenha aplicativos iOS, Android e web a partir de uma base de código—compare nativo, híbrido e PWAs, otimize desempenho e siga